Introducing Logical Intelligence, the company dedicated to making mission-critical software secure. We are rolling out two complementary AI agents built on our in-house research: Aleph, an AI formal verification agent that provides mathematical guarantees for code correctness, which can generate proofs that are tens of thousands lines long with 100% accuracy and provide visibility into a codebase’s current state; and Noa, an audit agent that highlights today’s vulnerabilities and demonstrates the need for stronger guarantees. In addition to these tools, we are developing a novel foundation model, Logical Intelligence 1.0 (LI-1.0), a non-autoregressive, energy-based model designed for mathematically precise reasoning, enabling the generation of formally verifiable code at scale. Our approach enables us to rapidly add support for new verification targets without spending thousands of engineering-hours, resulting in correct code in a fraction of the time of traditional methods. Most AI (like LLMs) solve problems one piece at a time—like doing a jigsaw blindfolded. If you place a piece wrong early, the whole picture suffers. LI-1.0 thinks differently: all the pieces move together, like magnets snapping into place until the puzzle is complete. Holistic, precise, scalable reasoning.
Currently we support multiple major smart-contract VMs as well as Rust and Golang programming languages, and are continuously working on expanding the supported use-cases with no human supervision. We envision the future where 100% of generated code is formally verified, ensuring complete security as more value enters the digital world.
Logical Intelligence has built a team of elite talent, including ICPC winners, world champions, and double world champions; Defcon CTF finalists; a Fields Medalist; IMC champions; and academic world leaders. Logical Intelligence thanks Mithril for providing scalable, dependable GPU infrastructure and exceptional support, and we are thrilled to announce our collaboration with the Solana Foundation 🚀.
Logical Intelligence will enable building fully-verified next-generation cryptographic protocols, including ones based on zero-knowledge proofs, and deliver the most private, secure software and hardware experience to the world. Aleph has already corrected multiple errors in proofs that serve as the foundation for existing and future security protocols in some of the world’s largest blockchains—collectively valued at over a trillion dollars in market capitalization—while also significantly improving these proofs beyond the initial corrections (see more in our blogpost). In principle, such a mistake could have compromised the security of these systems, potentially wiping out these assets. Formally verifiable systems that can push beyond the fallibility of even the most expert humans in safety-critical domains are now critical. In 2024 alone, with the help of AI agents, hackers stole nearly $1.5 billion from the crypto industry. Since 2017, total losses from attacks on DeFi platforms have reached an estimated $11.74 billion. These losses can be prevented with formal verification. Aleph can perform tens of thousands code lines (and more) of proofs with 100% accuracy and orders of magnitude faster than LLMs, right out of the box.
Aleph works by translating informal arguments about software correctness into machine-verifiable proof language Lean4. It is fully deterministic and guaranteed to be correct by the Lean4 proof checker, bypassing LLM hallucinations to ensure the safety and security of your code and/or digital assets against attacks.
How LI-1.0 AI Thinks: Magnetic‑Tile Reasoning
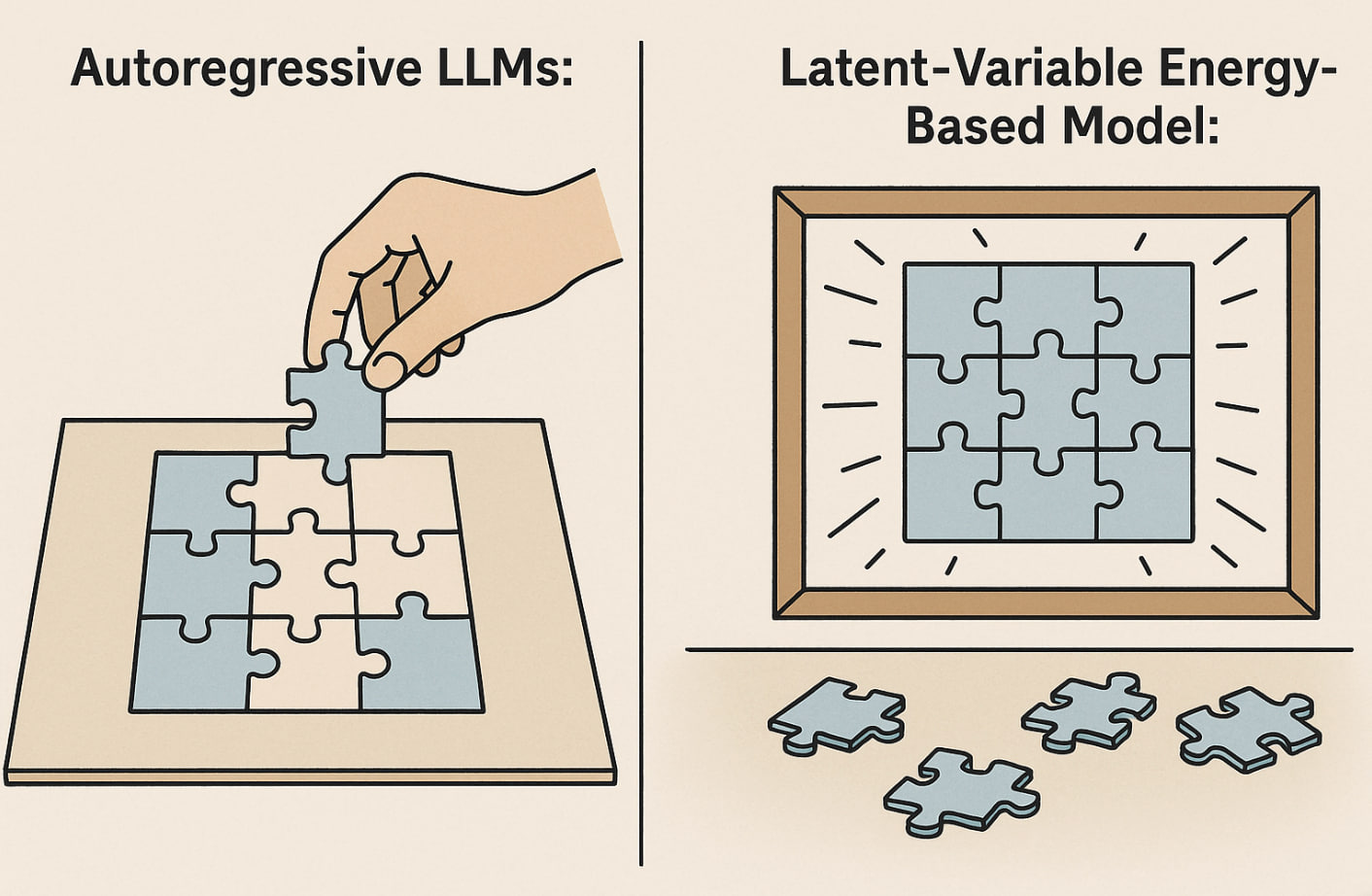
How it’s done by everyone else: Autoregressive Model (One Puzzle Piece at a Time):
Imagine you're solving a jigsaw puzzle blindfolded, placing pieces one by one. You pick a random piece and try to feel around the edge of the board, guessing where it might fit. Once you make a decision, you stick the piece in place—and you can't move it again. Then you grab the next piece and repeat the process. If you made a mistake early on, the whole puzzle might end up not fitting together, but you won’t realize it until it's too late. This is like an autoregressive model generating one word or token at a time—each new piece depends only on what came before, even if those earlier pieces were wrong. Typical language models like ChatGPT place each reasoning piece one by one, checking if it fits before moving on.
Our approach: LI-1.0 (All Puzzle Pieces Simultaneously):
Now imagine a magnetic puzzle board where every piece is gently tugged toward its correct position. You scatter all the pieces near the board, and each one instinctively “feels” where it belongs based on the full picture. They gradually slot into place, adjusting in response to one another, until they snap into a coherent configuration. If something feels off, the entire board can shift and refine the layout globally. This is like an energy-based model: reasoning is evaluated holistically, and every “tile”—whether a word, idea, or step—adapts to fit the overall structure, not just what came before. Our non-autoregressive latent‑variable Energy‑Based Model acts like a magnetic board: every piece feels the pull of the whole puzzle, snapping into its natural spot simultaneously. A handful of gradient steps nudge any strays, and the solution locks in—no step‑by‑step narration required.
Beating AI Attacks by Using AI Audit
Not convinced that your code needs formal verification? Our audit agent, Noa, is designed to uncover bugs that are notoriously difficult or even impossible to detect with traditional methods such as static analysis or fuzzing. Pilot users have already reported that Noa outperforms every audit tool they’ve tried. With seamless integration into your local IDE or GitHub environment, Noa enables you to trace underlying logic, catch errors early, and automatically generate a comprehensive report of all detected issues at a lower cost and with significant time savings. With Noa, you can improve performance and security without incurring all of the overhead of formal verification.
Follow our progress — sign up to learn about new benchmarks, case studies, and beta invites as they drop.
zk-SNARKs and Proof Automation
zk-SNARKs (for example Ligero) is a cryptographic technique that lets you prove heavy computations were done correctly without re-running them. In production (like on L1 blockchains), this means apps can run complex logic off-chain and only post a short proof on-chain, cutting transaction fees and speeding up confirmations.
It is described in this paper https://eprint.iacr.org/2022/1608.pdf, but unfortunately, the paper contains a mistake.
Our task was to prove a lemma (labeled 4.3 in the paper), formulated in Lean4, using our AI verification tool Aleph.

During the proof process, Aleph suggested that under the given conditions, the lemma is difficult to prove. However, if we correct the condition to |F| ≥ 2 * e + 1 instead of |F| ≥ e, the proof becomes significantly easier. After making this correction, Aleph was indeed able to prove the lemma.
It turned out that the proof in the original paper was actually valid under this corrected condition as well, but the lemma’s statement itself had been formulated inaccurately: in the proof, they show that there're at most 2 * e bad choices for α, and we can choose any other value - but it's only possible when |F| ≥ 2 * e + 1.
You can see our proof of this lemma here.
It is important to note that the total volume of the proofs amounts to almost 4000 lines. No human could even read through such a volume quickly. We, however, obtained the solution within just a few hours, relying solely on Aleph, without writing a single line of Lean4 code. And the Lean4 compiler confirms the correctness.